library(lobstr)2 Names and values
Introduction
厘清object和其name的区别十分重要,这可以帮助你:
- 精准地判断代码对内存的消耗。
- 理解代码运行缓慢的原因并优化。
- 更好理解R的函数式编程。
Tip
创建一个对象,你不需要使用<-来绑定一个名字。1:10能创建一个,x <- 1:10也能创建一个。
Outline
- 2.2节:介绍对象和其name的不同。
- 2.3节:copy-on-modify模式,使用
tracemem()追踪对象内存地址变化。 - 2.4节:R 对象消耗的内存,使用
lobstr::obj_size()查看占用大小。 - 2.5节:copy-on-modify模式的两个例外,环境对象和只有一个name的对象。
- 2.6节:使用
gc()释放内存。
Prerequisites
Sources
本章节的很多内容来自于下面3处:
- R documentation:
?Memory,?gc. - memory profiling in Writing R extensions.
- SEXPs in R internals
Binding basics
考虑下面的代码:
x <- c(1, 2, 3)
y <- x我们创建了一个名为x,值为1,2,3的对象,然后复制了一份讲其命名为y。那么,R在内存中是否也复制了一份,也即消耗了2倍的内存呢?事实上,此时消耗的内存并不是两倍,实际情况如下图所示。
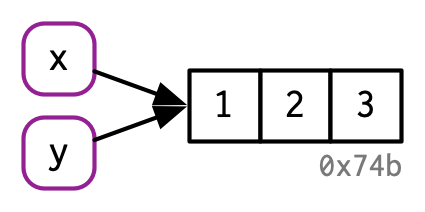
解释一下:
c(1,2,3)创建了对象,并占用内存,地址为0x74b。<-为对象绑定一个名字,即x。y <- x虽然将x复制了一份,但是x和y的值相同,都是对象c(1,2,3),所以内存地址是不变。
也即是说:内存和<-后面的对象有关系,后面的不变,内存地址不变,内存消耗几乎不变;<-前面的只是对象绑定的名字,因为实际的内存地址会随着终端变动而发生变动,需要绑定一个标签,你在代码的其他地方可以调用。
查看对象的地址可以使用lobstr::obj_addr(),当你运行时,结果肯定与我的结果不同,因为终端发生了变动。
obj_addr(x)
#> [1] "0x55d0df84afd8"
obj_addr(y)
#> [1] "0x55d0df84afd8"请注意:上述说的“x和y的值相同”,与“创建值相同的两个对象”不同。
a <- c(1, 2, 3)
b <- c(1, 2, 3)
obj_addr(a)
#> [1] "0x55d0e04a6578"
obj_addr(b)
#> [1] "0x55d0e04a5c18"Non-syntactic names
R 中对变量名的要求:必须由字母、数字、.、_构成,但_、数字、.+数字不能位于开头;不能使用关键字,查看关键字?Reserved;使用` 可以将任意字符包裹起来当作变量名;不建议使用'或"将变量名包裹。
_abc <- 1
if <- 10
`_abc` <- 1
`_abc`
`if` <- 10
`if`
#> Error in parse(text = input): <text>:1:2: unexpected symbol
#> 1: _abc
#> ^Exercises
- 下面所指的
mean函数内存地址都相同。
obj_addr(mean)
#> [1] "0x55d0d8d06cf0"
obj_addr(base::mean)
#> [1] "0x55d0d8d06cf0"
obj_addr(get("mean"))
#> [1] "0x55d0d8d06cf0"
obj_addr(evalq(mean))
#> [1] "0x55d0d8d06cf0"
obj_addr(match.fun("mean"))
#> [1] "0x55d0d8d06cf0"utils::read.csv()添加参数check.names = FALSE可以抑制列名的强制转换。make.names()在将非法名转换为合法名时,会遵循下面的规则:- 必要时添加前缀
X。 - 非法字符转换为
.。 - 缺失值转换为
NA。 - R中的关键字后添加
.。
- 必要时添加前缀
Copy-on-modify
诚如上述,当对象相同时,没有发生内存的消耗;但是如果对y进行了值得修改,那么内存会发生变动,如下所示。
y[[3]] <- 4
x
#> [1] 1 2 3
y
#> [1] 1 2 4
obj_addr(x)
#> [1] "0x55d0df84afd8"
obj_addr(y)
#> [1] "0x55d0e0e6d1c8"x绑定得原对象值未改变,R 创建新的对象,重新与y进行绑定。
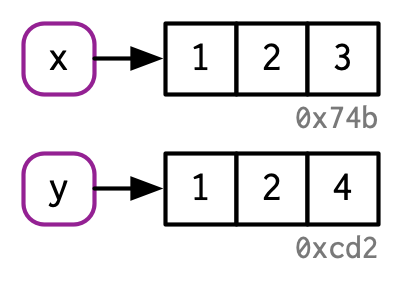
如果你修改多次对象,R 会创建多个新的对象,然后重新绑定,但是旧的对象不会消失,仍然存在于内存中,如下所示。
y[[3]] <- 5
obj_addr(y)
#> [1] "0x55d0e0c68198"
Note
请注意:在Rstudio中进行上述内存地址检查时,会有所不同。
tracemem()
tracemem()可以跟踪对象,在对象发生变动时显示变动情况,如下所示。
cat(tracemem(x), "\n")
#> <0x55d0df84afd8>
y <- x
y[[3]] <- 4L
#> tracemem[0x55d0df84afd8 -> 0x55d0df8f8288]: eval eval withVisible withCallingHandlers eval eval with_handlers doWithOneRestart withOneRestart withRestartList doWithOneRestart withOneRestart withRestartList withRestarts <Anonymous> evaluate in_dir in_input_dir eng_r block_exec call_block process_group withCallingHandlers <Anonymous> process_file <Anonymous> <Anonymous> execute .main
y[[3]] <- 5L使用untracemem()可以停止跟踪,如下所示。
untracemem(y)
y[[3]] <- 6LFunction calls
函数生成对象时遵循相同的规则,如下所示。
f <- function(a) {
a
}
cat(tracemem(x), "\n")
#> <0x55d0df84afd8>
z <- f(x)
# there's no copy here!
untracemem(x)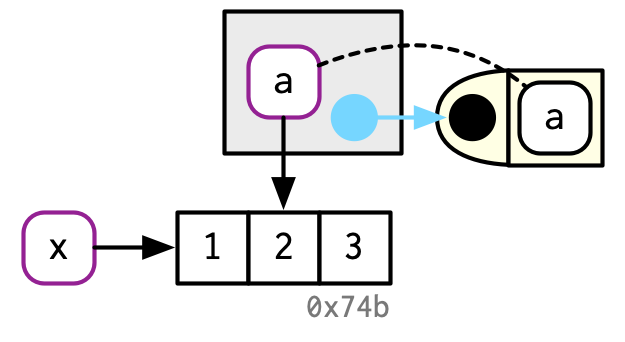
解释一下:
- 黄色部分表示函数,有参数
a。 - 灰色部分表示执行环境,返回函数运行后的结果
a。 - 因为返回结果和
x一致,没有改变对象,所以仍然绑定相同的对象。 - 当函数返回结果与
x不一致时,会创建新的对象,重新绑定。
Lists
与上面的向量不同,list格式的对象不仅本身有内存地址指定,它的元素也有内存地址指定。
下面是一个简单的list对象,虽然看似简单,但是在内存分配上却不简单。
l1 <- list(1, 2, 3)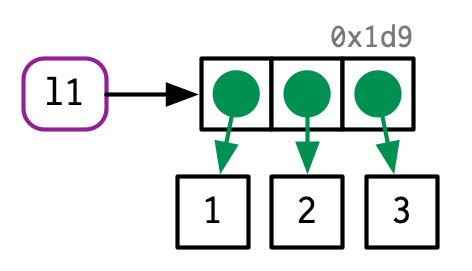
当复制list对象时,同样内存不会发生改变:
l2 <- l1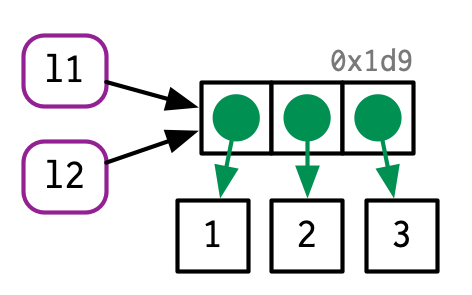
当复制的对象l2发生元素变动时,虽然R会创建一个新的内存地址,但同上面的情况略有不同:对list的复制是浅复制,不会复制所有的元素。与浅复制相对的是深复制,在R 3.1.0之前,都是深复制。
l2[[3]] <- 4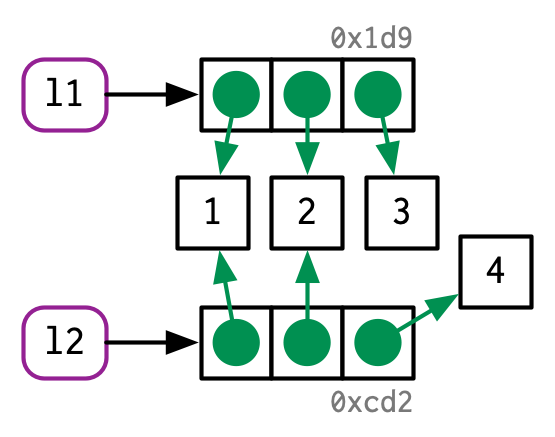
使用lobstr::ref()可以查看list中每个元素的内存地址。注意对一个list单独使用,和对两个list同时使用的结果中前面的数字有不同(自己尝试一下)。
ref(l1, l2)
#> █ [1:0x55d0e0ae7878] <list>
#> ├─[2:0x55d0e0f33df8] <dbl>
#> ├─[3:0x55d0e0f33c38] <dbl>
#> └─[4:0x55d0e0f33a78] <dbl>
#>
#> █ [5:0x55d0decabc68] <list>
#> ├─[2:0x55d0e0f33df8]
#> ├─[3:0x55d0e0f33c38]
#> └─[6:0x55d0de935b58] <dbl>关于list中的内存指向,你可以试着嵌套一些复杂的list,然后观察内存分配情况。
Data frames
data.frame 其本质就是list,所以它的行为同list一样。
d1 <- data.frame(x = c(1, 5, 6), y = c(2, 4, 3))
d2 <- d1
d2[, 2] <- d2[, 2] * 2
d3 <- d1
d3[1, ] <- d3[1, ] * 3
ref(d1, d2, d3)
#> █ [1:0x55d0dfd0a848] <df[,2]>
#> ├─x = [2:0x55d0dfc799f8] <dbl>
#> └─y = [3:0x55d0dfc799a8] <dbl>
#>
#> █ [4:0x55d0dfd42ee8] <df[,2]>
#> ├─x = [2:0x55d0dfc799f8]
#> └─y = [5:0x55d0dfcc9848] <dbl>
#>
#> █ [6:0x55d0dfd70f68] <df[,2]>
#> ├─x = [7:0x55d0dfd41b98] <dbl>
#> └─y = [8:0x55d0dfd41b48] <dbl>Character vectors
对于字符串类型的向量,R 使用全局字符串池来储存字符串。
x <- c("a", "a", "abc", "d")
y <- c("a", "d")
z <- list("a", "a", "abc", "d")
ref(x, character = TRUE)
#> █ [1:0x55d0e0566f78] <chr>
#> ├─[2:0x55d0d8d8bd90] <string: "a">
#> ├─[2:0x55d0d8d8bd90]
#> ├─[3:0x55d0d92ae280] <string: "abc">
#> └─[4:0x55d0d91f9d30] <string: "d">
ref(y, character = TRUE)
#> █ [1:0x55d0e0776c78] <chr>
#> ├─[2:0x55d0d8d8bd90] <string: "a">
#> └─[3:0x55d0d91f9d30] <string: "d">
ref(z, character = TRUE)
#> █ [1:0x55d0e0565a88] <list>
#> ├─█ [2:0x55d0df3484b8] <chr>
#> │ └─[3:0x55d0d8d8bd90] <string: "a">
#> ├─█ [4:0x55d0df3482f8] <chr>
#> │ └─[3:0x55d0d8d8bd90]
#> ├─█ [5:0x55d0df348138] <chr>
#> │ └─[6:0x55d0d92ae280] <string: "abc">
#> └─█ [7:0x55d0df347f78] <chr>
#> └─[8:0x55d0d91f9d30] <string: "d">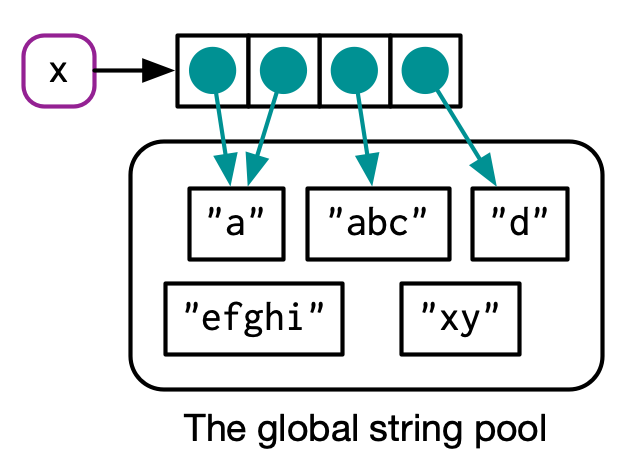
Exercises
1:10在内存中创建了对象,但是没有绑定,R无法对没有name的对象进行操作。x最先是integer类型,x[[3]] <- 4使用了double类型的数据替换,会导致R先复制一份double类型的向量,然后再替换数据。数据类型见下一章。
Object size
使用lobstr::obj_size()可以查看对象的大小。
obj_size(letters)
#> 1.71 kB
obj_size(ggplot2::diamonds)
#> 3.46 MBlist对象,因为有上述的浅复制机制,实际大小会与想象的不同。
x <- runif(1e6)
obj_size(x)
#> 8.00 MB
y <- list(x, x, x)
obj_size(y)
#> 8.00 MB上述对象中,y比x要略大一些,大约80b,因为包含了三份空元素的list大小是80b。
obj_size(list(NULL, NULL, NULL))
#> 80 B字符串向量也有相同的现象。
banana <- "bananas bananas bananas"
obj_size(banana)
#> 136 B
obj_size(rep(banana, 100))
#> 928 BExercises
…
Modify-in-place
诚如上述,当复制的对象发生值的改动,R会复制一份新,然后再修改值。但存在两个特例:
- 当对象只绑定了一个name时,会直接修改对象的值。
- 环境变量是一个特殊的对象,它总是直接修改对象的值。
Objects with a single binding
上面提到的“当对象只绑定了一个name时,会直接修改对象的值”,我在实际使用中,发现内存地址会发生变化。我简单的在不同系统中进行了实验,推测可能是系统原因。
v <- c(1, 2, 3)
lobstr::obj_addr(v)
#> [1] "0x55d0de95c0e8"
v[[3]] <- 4
lobstr::obj_addr(v)
#> [1] "0x55d0de9607e8"在R中存在下面两种情况,使得无法准确预测是否会发生复制:
- R 对于对象所绑定的name统计只能统计为:0,1,many;一旦对象绑定了多个name,那么就会始终被认为是many,无法回退。
- 绝大多数函数都会复制对象,除非是用C语言实现的函数。
例如下面的示例(按道理,上面的示例应该是不会发生变化的):
# 复制一份对象,a,b的地址是一样的
a <- c(1,2,3)
b <- a
lobstr::obj_addr(a)
#> [1] "0x55d0df898108"
lobstr::obj_addr(b)
#> [1] "0x55d0df898108"
# 当把名字a绑定另外一个对象后,在修改b的值,b的内存地址会发生变化
a <- c(2,3,4)
b[[3]] <- 4
lobstr::obj_addr(a)
#> [1] "0x55d0df983d48"
lobstr::obj_addr(b)
#> [1] "0x55d0df9f9588"上面所描述的对象复制过程,也是R base中for loop缓慢的原因,即for loop本身并不慢,而是因为每次循环都会发生复制修改对象的操作,导致运行缓慢。下面示例中每次循环都会发生两次复制,而转换为list结构时,总共只发生一次复制。
x <- data.frame(matrix(runif(5 * 1e4), ncol = 5))
medians <- vapply(x, median, numeric(1))# 每次循环都复制两次
cat(tracemem(x), "\n")
for (i in 1:5) {
x[[i]] <- x[[i]] - medians[[i]]
}
#> tracemem[0x564653d5bca8 -> 0x564656d3b6e8]:
#> tracemem[0x564656d3b6e8 -> 0x564656d3b838]: [[<-.data.frame [[<-
#> tracemem[0x564656d3b838 -> 0x564656d3b9f8]:
#> tracemem[0x564656d3b9f8 -> 0x564656d3bbb8]: [[<-.data.frame [[<-
#> tracemem[0x564656d3bbb8 -> 0x564656d3be58]:
#> tracemem[0x564656d3be58 -> 0x564656d3bf38]: [[<-.data.frame [[<-
#> tracemem[0x564656d3bf38 -> 0x564656d3c248]:
#> tracemem[0x564656d3c248 -> 0x564656d3c558]: [[<-.data.frame [[<-
#> tracemem[0x564656d3c558 -> 0x564656d3cc58]:
#> tracemem[0x564656d3cc58 -> 0x564656d37838]: [[<-.data.frame [[<-
untracemem(x)
# 总共复制一次
y <- as.list(x)
cat(tracemem(y), "\n")
#> <0x55d0db6c7c68>
for (i in 1:5) {
y[[i]] <- y[[i]] - medians[[i]]
}
#> tracemem[0x55d0db6c7c68 -> 0x55d0df9b5568]: eval eval withVisible withCallingHandlers eval eval with_handlers doWithOneRestart withOneRestart withRestartList doWithOneRestart withOneRestart withRestartList withRestarts <Anonymous> evaluate in_dir in_input_dir eng_r block_exec call_block process_group withCallingHandlers <Anonymous> process_file <Anonymous> <Anonymous> execute .mainEnvironments
环境变量储存着对象和name之间的绑定关系,它总是直接修改对象的值,不会进行复制。因为环境本质是一个查找表,存储变量名及其值,如果它们像向量或列表那样每次修改时都进行复制的话,会导致显著的性能开销。
e1 <- rlang::env(a = 1, b = 2, c = 3)
e2 <- e1
lobstr::obj_addr(e1)
#> [1] "0x55d0d98d3df8"
lobstr::obj_addr(e2)
#> [1] "0x55d0d98d3df8"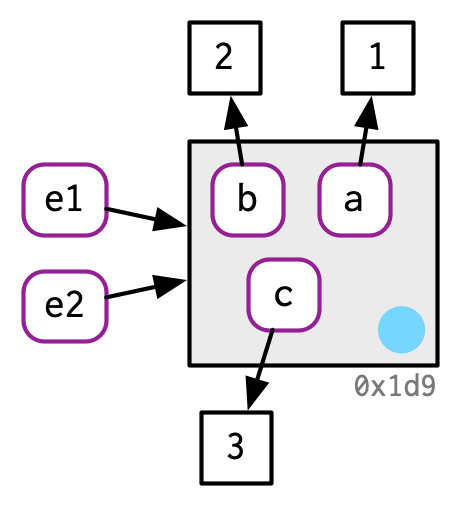
e1$c <- 4
e2$c
#> [1] 4
lobstr::obj_addr(e1)
#> [1] "0x55d0d98d3df8"
lobstr::obj_addr(e2)
#> [1] "0x55d0d98d3df8"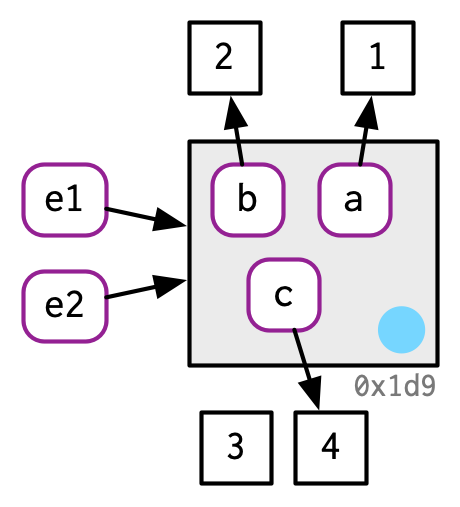
Unbinding and the garbage collector
关于garbage collector(gc),可以总结为以下几点:
rm()只是解除name绑定,不会清除对象。- R 环境中没有name绑定的对象,使用
gc()会被清除掉。 - R 会在内存不足时自动运行
gc(),使用gcinfo(TRUE)后,R每次gc()都会输出信息。 - 你无需手动运行
gc(),这是没有必要的操作。